

In today’s digitally driven landscape, automating ID data extraction from documents such as passports and other ID cards is vital for sectors like banking, travel, and government. PIT Solutions has developed a comprehensive, end-to-end AI-powered pipeline that captures essential information from images of identity cards – specifically UAE passports and UAE ID cards – and delivers the output as structured JSON objects, making it suitable for integration with downstream systems.
Technical Workflow for Passport and ID Card OCR
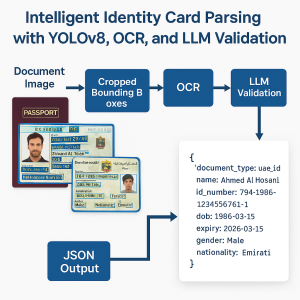
- Object Detection with YOLOv8
PIT Solutions adopted YOLOv8 (You Only Look Once version 8) for its cutting-edge performance in object detection tasks. Using YOLOv8 allowed us to:
- Detect various fields on IDs (e.g., name, photo, passport number) as individual bounding boxes.
- Handle multiple document layouts by training on annotated samples from both passport and ID cards.Annotation Process:
We used an online image annotation tool called Roboflow to annotate training samples, drawing bounding boxes around each required field. Each box was labeled with a class such as passport_no, en_name, ar_name, date_of_birth, photo, etc.
- OCR with EasyOCR
Traditional OCR often scans entire documents, leading to noisy outputs—especially when background text or multiple languages are present. By passing only the detected bounding boxes (cropped image regions) to OCR, we achieved:
- Reduced background noise.
- Increased accuracy for each field.
- Faster AI data extraction workflows.
We utilized EasyOCR due to its ease of integration and good support for English. For multi-language support (e.g., Arabic), we noted that EasyOCR’s performance can degrade; for production scenarios or non-English documents, an alternative like Google Vision OCR can be swapped in seamlessly.
- Validation with Local LLMs
As an optional but powerful enhancement, extracted data can be validated or corrected by passing the image and JSON result to a local Large Language Model (LLM) using solutions like Ollama with models such as Llama 4. This allows:
- Detection of OCR anomalies.
- Correction of minor transcription errors.
- Deploying the OCR Pipeline Locally
For demonstration and development purposes, the solution is deployed locally using:
- FastAPI as the backend service for inference and orchestration.
- Streamlit as a user-friendly frontend for uploading images and viewing results.
This setup not only showcases the power of modular, scalable architectures but also reflects our approach to custom software development, where we prioritize agility, user experience, and real-world applicability.
End-to-End Pipeline for Identity Document Extraction
The pipeline follows a streamlined flow for efficient document data extraction:
- Image Upload:
The user uploads an image of a passport or ID card via the Streamlit interface.

- Detection:
FastAPI backend invokes YOLOv8 to detect key fields and outputs bounding boxes with associated class labels and confidence scores. - Extraction:
Each detected region is cropped and passed to EasyOCR. The text is extracted field-by-field, minimizing cross-field confusion. - Optional Validation:
The complete JSON object and original image can be forwarded to an LLM for post-processing or validation. - JSON Output:
All extracted fields are returned as a structured JSON object.Sample Output:Below are real examples from our pipeline, showing both the detection overlay and the final JSON outputDetection Visualization

Each field (photo, name, passport number, etc.) is detected with a bounding box and labeled with the model’s confidence score.
Extracted Data (JSON)

The detected photo is returned as a base64-encoded image suitable for further processing or display, and fields are masked for data privacy.
Use Cases and Benefits of Automated ID Data Extraction
By applying advancements in AI & Data Science, this pipeline can be readily adapted for any organization needing fast, accurate extraction of ID data – especially in banking (KYC), government services (eKYC), travel/hospitality, and telecom.
Benefits:
- Eliminates manual data entry
- Accelerates onboarding
- Reduces human error
- Scales across multiple document types and languages
By using AI-powered OCR data extraction, organizations can unlock new efficiencies in compliance-heavy and document-intensive workflows.
Conclusion
This project showcases how PIT Solutions combines modern object detection (YOLOv8), targeted OCR techniques, and optional LLM-based validation to create a robust solution for automated ID data extraction. The modular architecture allows easy customization for new document types – helping organizations streamline customer onboarding and compliance processes with high accuracy and reliability.
Ready to modernize your onboarding workflow with AI-powered document automation? Contact PIT Solutions for a custom demo.